개념
지도, 비지도, 강화 학습
- 지도 학습

옆에서 훈수를 계속 해준다
인간이 교사가 되어 각각의 입력에 대해 레이블을 달아놓은 데이터를 컴퓨터에 주면 컴퓨터가 그것을 학습하는것이다. 크게 분류와 회귀 모델이 있다.
- 비지도학습
혼자서 하는 게임
사람 없이, 컴퓨터가 스스로 레이블되지 않은 데이터를 학습하는것. 정답이 없는 문제인지라 학습이 잘 됐는지 확인할수는 없지만 인터넷의 거의 모든 데이터가 레이블되지 않았기에 앞으로 기계학습이 나아갈 방향이기도 하다.
- 강화학습

옆에서 잘했다/못했다를 알려준다
현재 상태에서 어떤 행동을 취하는것이 최적인지를 학습한다. 행동을 취할때마다 외부에서 보상이 주어지며 이를 최대화하는 방향으로 진행된다.
딥러닝?
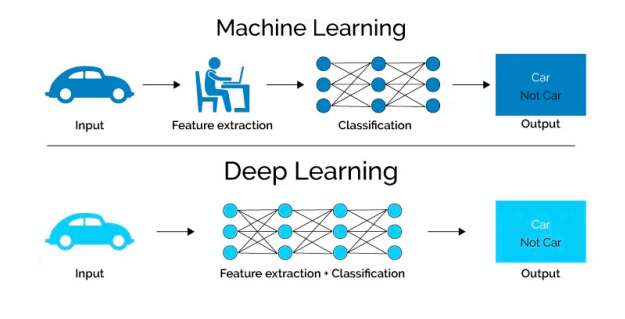
간단히 많은 양의 데이터를 통해 스스로 학습하는것이라 할수있다.
마운틴카
환경 정의하기
오늘 수업에서는 강화 학습의 가장 단순하고 유명한 예제 중 하나인 `Mountain Car”문제를 풀어보았다. 이 문제의 목표는 산 정상의 깃발에 도달하는 것이다. 여기서 왼쪽, 오른쪽으로 가속하는 페달을 밟거나, 밟지 않는 선택을 할수 있다. 산 정상까지 올라가려면 페달을 적절히 밟아야 한다. 하지만 산의 경사가 너무도 가파르기 때문에 단순하게 밟는것으로는 중력때문에 올라가지 못할 수 있다.

먼저 이 환경에서 취할 수 있는 행동은 다음과 같이 표현할 수 있다.
0: 왼쪽으로 가속하는 페달 밟기
1: 페달 밟지 않기
2: 오른쪽으로 가속하는 페달 밟기
env = gym.make('MountainCar-v0')
print('Created env:', env)
print('Available actions:', env.action_space) #행동의 개수
x축 방향의 좌표는 $(-1.2, 0.6)$ 사이이고, 속도는 $(-0.07, 0.07)$ 사이이다.
action = 0 # 왼쪽으로 가는 행동을 선택
# 행동 선택 후 다음 상태, 보상, 환경이 끝난지에 대한 정보, 뒤에 _ _는 지금 배우지 않음
state, reward, done, _, _ = env.step(action)
print(f"State: {state}") # [다음 x축 좌표, 다음 속도]
print(f"Reward: {reward}")# 다음 보상
print(f"Done: {done}") # 환경이 끝났는지?
인공지능 정책 정의하기
강화 학습에서 정책은 인공지능의 두뇌이다. 가장 단순한 형태의 정책은 아무거나하는것이다.
# 아무거나 하는 정책
class RandomPolicy(): # 아무거나 하겠다
# 클래스 선언
def __init__(self, action_space):
# 행동 공간에 대한 정보 저장
self.action_space = action_space
self.name="RandomPolicy()"
# 클래스 호출 함수
def __call__(self, state):
global graph1
graph1.append(state[1])
# 상태 (state)를 받았을때 어떤 행동을 취할지 결정하는 함수
# 여기선 랜덤한걸 선택
return self.action_space.sample()
또한 다음은 수업에서 예시로 든 정책이며, 작동 방식은 다음과 같다.
- 속도가 0일때
-
- 시작 위치의 왼쪽이라면 오른쪽으로, 오른쪽이라면 왼쪽으로, 둘다 아니라면 왼쪽으로 가속한다.
- 속도가 0이 아닐경우 왼쪽으로 가속한다
class ExamplePolicy(): def __init__(self, action_space): self.action_space = action_space self.name="ExamplePolicy()" #새로정의하는 상수 self.start_position=-0.6 def __call__(self, state): # 밟는데 안움직이면 전환하는법 global graph1 graph1.append(state[1]) x,v = state next_action=0 if v ==0: if x < self.start_position: my_action=0 next_action = 2 elif x > self.start_position: my_action=2 next_action = 0 else: my_action=1 next_action = 0 return next_action
그리고 마지막으로, 직접 설정한 정책이다. 속도가 음수라면 (왼쪽으로 가는 중이라면) 왼쪽으로 가속하며, 양수라면 (오른쪽으로 가는 중이라면) 오른쪽으로 가속한다. 둘다 아니라면 오른쪽으로 가속한다.
graph1=[]
graph2=[]
class Policy1():
def __init__(self, action_space):
self.action_space = action_space
self.name="Policy1()"
def __call__(self, state):
global graph1
global graph2
graph1.append(state[1])
graph2.append(state[0])
x,v = state
if v>0:
action = 2
elif v<0:
action = 0
else:
action = 2
return action
환경과 상호작용하기
강화 학습에서는 어떤 행동을 취한다면 환경은 보상을 준다. 또한 취한 행동에 따라 환경은 변화하고, 이 환경을 다시 관찰할수 있으며, 이를 반복해 진행한다.
# 환경을 생성
env = gym.make("MountainCar-v0", render_mode="rgb_array")
# 비디오 저장을 위해
env = RecordVideo(env, 'video', name_prefix='random-agent')
#정책 불러오기
# agent = RandomPolicy(env.action_space)
agent = Policy1(env.action_space)
# agent = ExamplePolicy(env.action_space)
state, _ = env.reset()# 환경 초기화
env.start_video_recorder() # 비디오 촬영 시작
graph1=[]
graph2=[]
done=False
# for t in range(1000):
while not done:
action = agent(state) # 상태정보를 받아 행동 결정
state, reward, done, _, _ = env.step(action) # 행동에 의해 상태 변화
env.render() # 비디오 촬영
env.close()
view_video('random-agent')
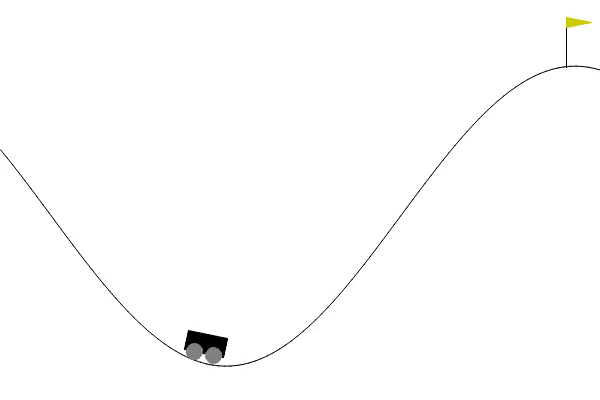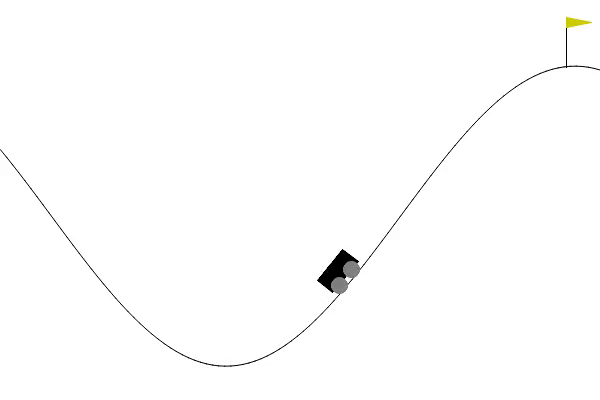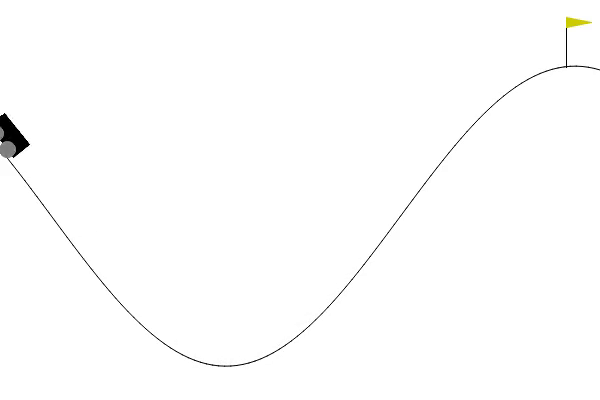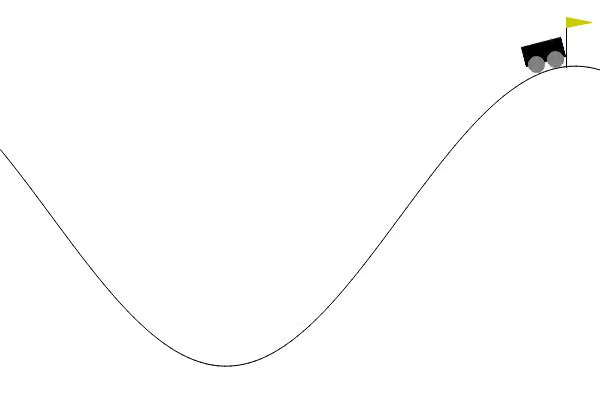
# 시각화
plt.title(agent.name)
# print(len(graph1))
plt.text(len(graph1)-2, graph1[-1], str(len(graph1)))
plt.plot([i for i in range(len(graph1))], list(map(lambda x: x*20-0.4, graph1)))
plt.plot([i for i in range(len(graph2))], graph2)
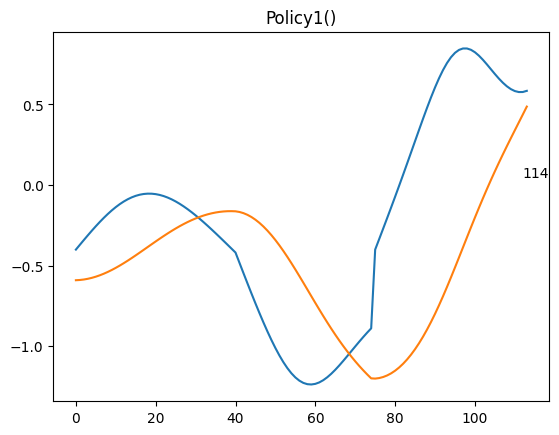
직접 만든 정책을 통하여 문제를 푸는데 성공했다.
그리고 괜히 보고싶어져서 그래프를 통한 시각화까지 했다.
(파란 선은 속도*20, 주황 선은 x위치)
강화 학습 환경 직접 만져보기
블랙잭
end=0
number1=50000
for i in range(number1):
# 블랙잭 환경 생성
env = gym.make('Blackjack-v1')
# 환경 초기화
state, _ = env.reset()
# print(f"초기 상태: {state}")
done = False
while not done:
# 랜덤 행동 선택 (for 루프 사용하지 않음)
action = Policy1(state)
# print(f"액션: {action}")
# 환경에서 행동 수행
state, reward, done, info, _ = env.step(action)
# 현재 상태, 보상, 게임 종료 여부 출력
# print('상태:', state,'보상:', reward, '게임 종료:', done)
# 환경 닫기
env.close()
if done:
if reward==1.0:
end+=1
# print("="*20)
print(f"{number1} 실행 후 {end}번 승리, 승률 {end/number1}")
50000회 실행 후 19597번 승리, 승률 0.39194
import random
def Policy1(state):
currentSum, dealer, ace=state
rand1=random.randint(1, 12)
if rand1==12:
if currentSum==21:
action=0
else: action=1
elif currentSum>8 and currentSum<12:
if currentSum<12:
action=1
else: action=0
elif currentSum+rand1<21:
action=1
else:
action=0
return action
블랙잭의 규칙이 생각보다 복잡해서 일부분만 완성했다. 뽑을 때 실패하지 않는 경우는 무조건 뽑고, 그렇지 않는경우 확률에 따라 뽑는다.
소감
본격적인 강화 학습에 대해 배우기 전에 기본적인 원리를 알아보며 강화학습의 과정을 대신해 알고리즘을 통해 문제를 풀어보니, 재밌긴 하면서도 이런 번거로운 과정을 줄이고 컴퓨터가 대신 일하게 한다는게 인공지능의 멋진점같았다.